
Auto-PPA: An Adaptive Deep RL Agent for VLSI Physical Design Optimization
DOI:
https://doi.org/10.31838/JCVS/08.01.02Keywords:
VLSI, Optimization, AI model, Reinforcement Learning, Real-Time PPA Co-OptimizationAbstract
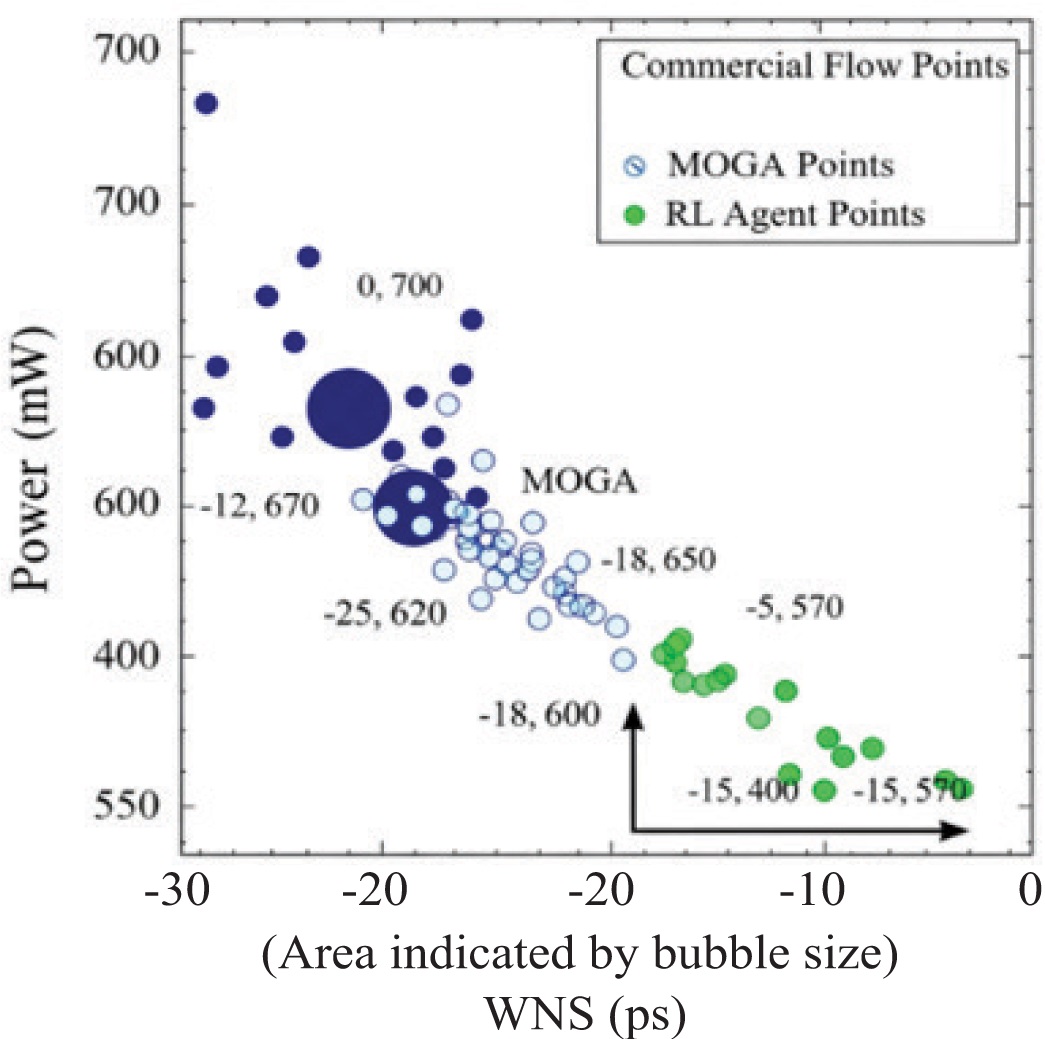
The physical design phase of Very-Large-Scale-Integration (VLSI) is notoriously difficult since it must strike a balance between PPA, power, and performance. Computationally costly design cycles and less-than-ideal Pareto fronts are common challenges of using traditional optimization methods to tackle these metrics in order. As part of physical design, this study suggests a new reinforcement learning (RL) framework that can optimize all three PPA measures in real time. In the proposed method, commercial electronic design automation (EDA) tools were used in conjunction with a deep deterministic policy gradient (DDPG) agent to make routing and placement decisions incrementally. Guided by a customized reward function that dynamically balances PPA trade-offs based on design stage priorities, the agent operates on a continuous action space that represents geometric coordinates and constraint modifications. While conventional sequential optimization methodologies reduce optimization runtime by about 35%, the proposed RL agent improves the power-performance product by 18.7% and the area reduction by 12.3%, according to simulation results on the ISPD 2015 benchmark suite. An innovative approach to optimize intelligent, adaptable physical designs that successfully traverse the high-dimensional PPA trade-off space is presented by the suggested framework.
Published
How to Cite
Issue
Section









