
Design and Optimization of Coarse-Grained Reconfigurable Array (CGRA) Architecture for Efficient Processing-in-Memory (PIM) Systems
DOI:
https://doi.org/10.31838/jvcs/07.01.02Keywords:
Processing-in-Memory (PIM), Coarse-Grained Reconfigurable Array (CGRA), memory wall, Design Space Exploration (DSE), Energy efficiencyAbstract
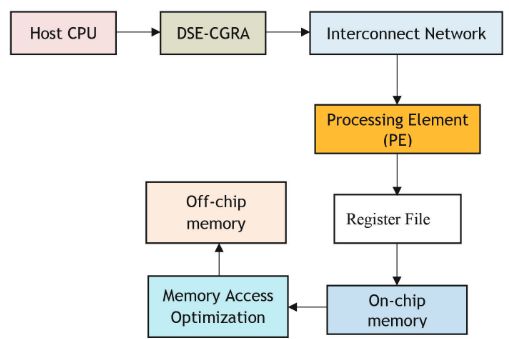
The Coarse-Grained Reconfigurable Array (CGRA) architecture for Efficient Processing-in-Memory (PIM) systems is presented in this article. PIM architectures that incorporate computational capabilities directly into memory present a promising solution to mitigate the memory wall issue. There are several difficulties in CGRA architecture optimization for PIM systems especially when it comes to striking a balance between area efficiency, power consumption and performance. The proposed framework tackles these problems by examining crucial design components like processing element (PE) architecture memory hierarchy integration and interconnect design. Using a design space exploration (DSE) methodology we assess various CGRA configurations to find the optimal trade-offs between computation throughput, power consumption and silicon area utilization. To assist in selecting effective architectures that meet different application workloads the framework combines performance analysis and advanced modeling techniques. Based on test results, the optimized CGRA architecture for PIM achieves significant improvements in processing performance (20 percent increase in throughput), area reduction and energy efficiency (up to 40 percent reduction in power consumption) when compared to conventional PIM designs. Our architecture is well-suited for data-intensive applications such as machine learning and graph analytics since these enhancements are achieved without compromising computational accuracy or scalability.
Downloads
Published
How to Cite
Issue
Section










